RefFusion: Reference Adapted Diffusion Models for 3D Scene Inpainting
Abstract
Neural reconstruction approaches are rapidly emerging as the preferred representation for 3D scenes, but their limited editability is still posing a challenge. In this work, we propose an approach for 3D scene inpainting---the task of coherently replacing parts of the reconstructed scene with desired content. Scene inpainting is an inherently ill-posed task as there exist many solutions that plausibly replace the missing content. A good inpainting method should therefore not only enable high-quality synthesis but also a high degree of control. Based on this observation, we focus on enabling explicit control over the inpainted content and leverage a reference image as an efficient means to achieve this goal. Specifically, we introduce RefFusion, a novel 3D inpainting method based on a multi-scale personalization of an image inpainting diffusion model to the given reference view. The personalization effectively adapts the prior distribution to the target scene, resulting in a lower variance of score distillation objective and hence significantly sharper details. Our framework achieves state-of-the-art results for object removal while maintaining high controllability. We further demonstrate the generality of our formulation on other downstream tasks such as object insertion, scene outpainting, and sparse view reconstruction.
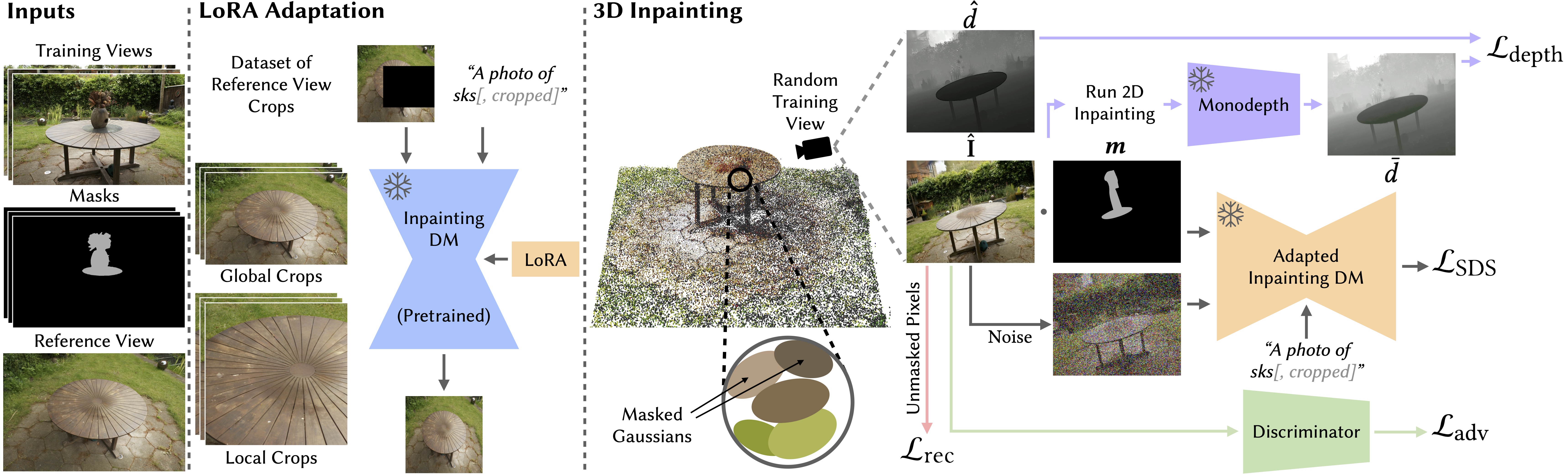
Overview of the proposed approach.
Inpainting Results
Qualitative 3D inpainting results on the SPIn-NeRF dataset.
Input Scene
Sample Mask
Inpainted Scene





Previous
Next
Object Insertion Results
We demonstrate object insertion capabilities of our method by using a reference view with an added object in the masked region, obtained using a text-to-image inpainting diffusion model. Our method succeeds in distilling the specified object into the scene with high visual fidelity.
Input Scene
Reference View
Output Scene


Previous
Next
Outpainting Results
We generate inverse masks by placing a sphere at a fixed distance along the optical axis and checking for ray-sphere intersection. Given this mask, we task our method to outpaint the scene using the same formulation and hyperparameters used for object removal. Our method completes the scene in a plausible manner.
Input Scene
Sample Mask
Outpainted Scene

Sparse View Reconstruction
To investigate the benefits of our method for guiding the sparse view reconstruction, we consider a scene with an unwanted occluder where only a small set of clean images from the scene (GT views) is available. We show that while 3D Gaussian Splatting (3DGS) fails to reconstruct the masked region using sparse view supervision, our model acts as a prior to alleviate the lack of enough training views, enabling sharp reconstructions with as few as a single GT view.
Masked Scene
Output (1 GT View)



Previous
Next
|
|